Breve descripción del medio ambiente
Una vez más nos encontramos en el ambiente que hemos denominado como Biokterii. El medio ambiente consiste en el interior de un cuerpo de un ser vivo, donde un virus debe aprender a realizar ciertas acciones con las células que irán apareciendo dependiendo del color de las mismas. Existen tres tipos de células, las de color rojo son consideradas como objetivos o Target, las células de color azul son consideradas comida o Food y por último las células de color verde son las equivalentes a los glóbulos blancos y son consideradas enemigos o Enemy.
Descripción detallada de la actividad o acción que va a aprender tu agente
El agente aprenderá, utilizando aprendizaje por refuerzo, a realizar ciertas acciones dependiendo del tipo de célula que aparezca. El virus cuenta con tres acciones, atacar, comer y defenderse y además cuenta con cuatro estados dependiendo su nivel de vida: alto, medio, bajo y muerto. Cuando el virus se encuentra en el estado alto puede atacar o comer, cuando se encuentra en el estado medio puede comer o defenderse, cuando esta en el estado bajo puede comer o defenderse y cuando esta muerto no puede realizar ninguna acción. Lo ideal es el que el virus aprenda a tomar las decisiones correctas que le permitan sobrevivir en el ambiente la mayor cantidad de tiempo posible y destruyendo la mayor cantidad posible de células.
Selección de la experiencia de aprendizaje
El virus aprenderá a realizar ciertas acciones (atacar, comer, defenderse) dependiendo de su estado. El objetivo es que permanezca vivo y destruya la mayor cantidad de células posibles.
Las acciones y los estados posibles son modelados con la siguiente tabla.
Estado
Acción
A
Nuevo estado
Alto Atacar Rojo Alto
Alto Comer Rojo Medio
Medio Comer Rojo Medio
Medio Defender Rojo Bajo
Bajo Comer Rojo Bajo
Bajo Defender Rojo Bajo
Alto Atacar Azul Bajo
Alto Comer Azul Alto
Medio Comer Azul Alto
Medio Defender Azul Medio
Bajo Comer Azul Medio
Bajo Defender Azul X
Alto Atacar Verde Medio
Alto Comer Verde Bajo
Medio Comer Verde Bajo
Medio Defender Verde Alto
Bajo Comer Verde X
Bajo Defender Verde Medio
Selección de las recompensas
La forma resumida de explicar las recompensas es que todas las recompensas son 0 excepto cuando estando en un:
* Estado Alto ataca una célula roja = +100
* Estado Alto come una célula azul = +50
* Estado Medio come una célula azul = +100
* Estado Medio se defiende de una célula verde = +50
* Estado Bajo se defiende de una célula azul = -100
* Estado Bajo se come una célula verde = -100
Posibles acciones de tu agente en el medio
Las acciones del virus dependen del estado en que se encuentre, definiéndolo de una manera más formal, son las siguientes:
V(Alto) = {atacar, comer}
V(Medio) = {comer, defenderse}
V(Bajo) = {comer, defenderse}
V(Muerto) = {}
Estados posibles que puede sensar tu agente en el medio (descripción de los estados)
El virus puede saber el color de la célula que se encuentra en el ambiente y su cantidad de vida. Todas las células se pueden comer, atacar o defender, sin embargo los resultados varían dependiendo del color de la misma.
Estados: Alto, Medio, Bajo.
Alto. En este estado el virus se encuentra a su máxima capacidad, puede realizar las accionede de atacar o comer.
Medio. Es cuando el virus ha sufrido algún daño, puede realizar las acciones de comer o defenderse.
Bajo. Cuando el virus ha sufrido serios daños, sólo puede comer o defenderse, pero se encuentra a un paso de la muerte.
Muerte (X). Es cuando el virus ya pasó a mejor vida por tomar malas decisiones.
Descripción de la estrategia de exploración/explotación para el aprendizaje.
Para lograr un equilibrio entre la exploración y explotación se está siguiendo una política implementada por nosotros, dicha política consiste en usar el nivel de explotación de acuerdo al porcentaje que se encuentra la tabla Q. Es decir, al principio, cuando la tabla Q está vacía, siempre se elige una acción al azar, después cuando la tabla Q se encuentra justo medio llene, existe el 50% de probabilidad de que elija una acción al azar o una dictada por el uso de las recompensas de la tabla Q. Cuando la tabla se encuentra completamente llena siempre elige una acción basada en lo que aprendió.
Ejemplo de tres estados distintos del medio ambiente, con las respectivas acciones que pueden ser realizadas desde dicho estado y las recompensas que se le otorgan al agente al tomar las acciones.
Ejemplo 1
El virus se encuentra en estado Alto y aparece una célula Roja (las células rojas son definidas en nuestro ambiente como objetivos o Target). Al encontrarse en estado alto sólo puede realizar las acciones de atacar o comer, cada acción depende del color de la célula con la que va a interactuar. Si al principio la tabla Q se encuentra vacia se realizará una acción al azar, sin embargo lo ideal es que ataque a la célula roja pues es la única acción que le da una recompensa inmediata de 100 puntos; la otra acción posible que es comer la célula roja no le da absolutamente ninguna recompensa.
Ejemplo 2
Vamos a suponer que nuestro virus se encuentra en un estado Medio y aparece una célula Azul (las células azules son consideradas como comida o Food). Al encontrarse en un estado Medio el virus puede comer o defenderse, en este caso, el virus recibe una recompensa de 100 puntos si es que se come la célula azul y ninguna recompensa si es que se defiende de el.
Ejemplo 3
Para este caso el virus se encuentra en un estado Bajo y aparece una célula Verde (las células verdes son los glóbulos blancos o los Enemy). Al econtrarse en estado Bajo el virus puede comer o defenderse. Si el virus decide defenderse no recibe ningún punto, pero si el virus decide comerse a la célula verde recibirá una penalización de -100 puntos.
Explicar cuándo es que tu agente va aprendiendo y cuándo utiliza lo aprendido para tomar decisiones en el medio.
El agente va aprendiendo cada episodio, (dicho episodio se termina cada que el virus realiza una acción y en este momento es cuando se le da un refuerzo) utilizando el algoritmo de Q learning y llenando la tabla correspondiente, después de varias iteraciones el virus es capaz de tomar las decisiones correctas para poder sobrevivir en el ambiente dependiendo de la célula a la que se enfrenta. Como se menciono anteriormente se implementó una politica, la cual permite que conforme se va llenando la tabla Q mayor sea la probabilidad de elegir una acción basado en lo que se ha aprendido. Como se explicó anteriormente, se trata de una relación directa entre el porcentaje de celdas llenas y la probabilidad de que se siga lo aprendido, al estar vacia la tabla se elegirán siempre acciones al azar, al estar el 50% llena habrá 50% de probabilidad de que se elija una acción al azar o de que se siga lo aprendido y cuando la tabla se encuentra llena la probabilidad de que se seleccione una acción basada en lo aprendido es de 1.
Conclusiones después de la programación
Este ha sido uno de los problemas más difíciles a los que nos hemos enfrentado en este curso, sobre todo en la parte del planteamiento del problema, pues para evitar que fuera trivial queriamos implementar acciones y estados que elevaban exponencialmente la complejidad del mismo. Al final y después de dos días de plantearlo logramos llegar a una solución que no era del todo sencilla y que lograba un aceptable grado de dificultad. Tambien dicho problema se nos complicó un poco debido a que sólo enconntrabamos ejemplos de laberintos por todas partes y tal vez sentimos que nos falto estudiar otros ejemplos en clase.
Video
Tuesday, May 11, 2010
Monday, May 10, 2010
QLearning - Equipo 3
QLearning - Aprendizaje por refuerzo
Bárbara Cervantes 1161223
Gerardo Basurto 1013754
Félix Horta 1162183
Descripción del medio ambiente
Un "ghost" desea explorar un ambiente desconocido en busqueda de enemigos. Los enemigos se encuentran dispersos en el ambiente de forma no uniforme. El heroe se encarga de explorar aleatoriamente el ambiente aprendiendo de las batallas. A través de la experiencia aprende a correr y cuando confrontar una batalla para salir victorioso. El ambiente considera el estado actual del heroe y el estado actual de su enemigo justo al comenzar una batalla.
Descripción de la actividad que aprenderá el agente
El heroe ( agente ) debe ser capaz de reconocer las batallas que puede ganar. Asi como el momento en el cual retirarse de una batalla. Su misión es cazar enemigos, no obstante para hacer su misión debe permanecer con vida. El agente en consecuencia, aprende a tomar las acciones adecuadas dependiendo al estado actual de la batalla. El agente posee dos acciones :
- Atacar ( confrontar al enemigo )
- Huir ( dejar la batalla y regresar al punto seguro del mapa )
Descripción detallada de los patrones
Un patrón está formado de la siguiente manera:
{ EstadoHeroe, EstadoEnemigo } -> Acción
Donde:
EstadoHeroe. Clasifica el estado del heroe dependiendo a su salud actual. Puesto que su salud consiste en valores continuos al inicio de la partida se generan randos para determinar y catalogar en que estado se encuentra. Su salud puede estar:
- Alta (0)
- Media (1)
- Baja (2)
- Muerto (3)
EstadoEnemigo. De la misma manera que el estado heroe clasifica el estado del enemigo en base a su salud en dicho instante.
Q-Learning. Diseño del Ambiente.
Para realizar aprendizaje por refuerzo utilizando Q-Learning se definió en principio la matriz de estados posibles en el ambiente. La matriz del ambiente es la siguiente:
mAmbient[0].initState(QLearning::high,QLearning::high);
mAmbient[1].initState(QLearning::high,QLearning::low);
mAmbient[2].initState(QLearning::high,QLearning::normal);
mAmbient[3].initState(QLearning::high,QLearning::dead);
mAmbient[4].initState(QLearning::normal,QLearning::high);
mAmbient[5].initState(QLearning::normal,QLearning::low);
mAmbient[6].initState(QLearning::normal,QLearning::normal);
mAmbient[7].initState(QLearning::normal,QLearning::dead);
mAmbient[8].initState(QLearning::low,QLearning::high);
mAmbient[9].initState(QLearning::low,QLearning::low);
mAmbient[10].initState(QLearning::low,QLearning::normal);
mAmbient[11].initState(QLearning::low,QLearning::dead);
mAmbient[12].initState(QLearning::dead,QLearning::high);
mAmbient[13].initState(QLearning::dead,QLearning::low);
mAmbient[14].initState(QLearning::dead,QLearning::normal);
mAmbient[15].initState(QLearning::dead,QLearning::dead);
Donde:
- Se poseen 16 estados, que es la combinación de 4x4 de acuerdo a los 4 posibles estados que pueden tomar las unidades.
- Dado el arreglo estático de estados en el ambiente, es posible dejar a la aplicación correr y solo realizar una nueva acción cuando se detecta un cambio en el estado del ambiente. Este ultimo punto reduce considerablemente el poder computacional necesario. Otorgando un enfoque basado en eventos, detectando unicamente cuando el estado del ambiente ha cambiado; descartando asimismo toda la información inecesaria para el aprendizaje.
Matriz de recompensa.
Se diseño una matriz de recompensa para cada estados de la siguiente forma:
mRewards[0] = 0; // punish this state
mRewards[1] = 10;
mRewards[2] = 12;
mRewards[3] = 100; // High - Dead
mRewards[4] = 20;
mRewards[5] = 10;
mRewards[6] = 10;
mRewards[7] = 85; // Normal - Dead
mRewards[8] = 30; // low - h
mRewards[9] = 20; // low - med
mRewards[10] = 10; // low - low
mRewards[11] = 70; // Low - Dead
mRewards[12] = 0; // punished states
mRewards[13] = 0;
mRewards[14] = 0;
mRewards[15] = 0;
Donde:
- Cada entrada define la recompensa por el estado correspondiente. Todos los estados poseen cierto grado de recompensa excepto los estados negativos.
- Para castigar los estados en los cuales el agente muere, se les otorgó una recompensa de 0. Los estados con mayor recompensa son aquellos en los que el jugador sobrevive y derrota a su enemigo.
- Estados intermedios obtienen una ligera recompensa para incentivar el "huir" de partidas peligrosas, asegurando la sobreviviencia del agente.
Conclusiones
El entrenamiento funciona adecuadamente para el agente. El agente es capaz de reconocer distintos tipos de enemigos y generar entrenamientos especificos para cada nuevo tipo de enemigo con el cual se le presenta. Asimismo conforme explora el ambiente y las distintas modificaciones sobre las cuales puede darse una batalla comienza a generar un robusto entrenamiento que le permite sobrevivir una gran mayoria de las batallas enfrentadas.
Cabe señalar que curiosamente, el agente aprende rapidamente que para "permanecer vivo" cuando tiene poca salud es conveniente no combatir en lo absoluto. Con esto, el agente huye de todas las batallas cuando sabe que seguramente fallecera de llevar la batalla a cabo. Por esta razón, llega un momento en el cual si el agente esta a punto de fallecer comienza a huir de todas las batallas.
Mediante la implementación de QLearning en starcraft demostramos que es posible implementar un algoritmo de aprendizaje en tiempo real para un videojuego de estrategia en donde un agente es capaz de sensar el medio y aprender de las decisiones tomadas en el pasado. Esto abre una interesante puerta para nuevas aplicaciones de aprendizaje por refuerzo. Concluimos que aprendizaje por refuerzo es una muy poderosa herramienta que puede ser utilizada para una amplia gama de aplicaciones distintas, las posibilidades son tan grandes como nuestra capacidad de abstraer el aprendizaje y modelar nuevos ambientes sobre los cuales se puede realizar.
Videos
Thursday, May 6, 2010
Q-Learning, Aprendizaje por Refuerzo
Medio Ambiente:
Nuestro medio ambiente será como un tipo calabozo con forma de laberinto (el cuál será dinámico), constará de una entrada y dos tipos de agentes principales: buscador (agente verde) y guardián (agente rojo). También dentro del calabozo se encuentra un objeto que el buscador debe obtener (cuadro azul obscuro).
El objetivo del buscador será evitar a los guardias el mayor tiempo posible y a la vez, donde los callejones sin salida influirán a veces si es atrapado o no. El buscador debe encontrar el objetivo para de esta manera “ganar”.
En cuanto el agente buscador es atrapado por alguno de los guardianes, este regresa al inicio. También al encontrar el objetivo el buscador regresara a la entrada.
Actividad que aprende:
En este caso el agente aprenderá a moverse dentro del medio ambiente intentando acercarse lo más posible al objetivo.
Experiencia de Aprendizaje:
En este caso se utilizó el algoritmo de Q-Learning para que el agente buscador aprenda a encontrar su camino al objetivo (cuadro azul obscuro). El calabozo está situado en un cuadro de 40x40 donde el agente y los guardianes solo se mueven en los números impares, esto es coordenadas impares. Dado al tamaño el aprendizaje puede ser muy lento de acuerdo a los episodios seleccionados. Para esto se utiliza una variable entera, si esta es 1 quiere decir que el buscador obtuvo el objetivo, si es 2, significa que el buscador fue atrapado por uno de los guardias. Esto marca los episodios del aprendizaje.
Recompensas:
Las recompensas elegidas fueron las siguientes:
Si el movimiento elegido deja al buscador en la posición del objetivo, su recompensa es 100.
Si el movimiento elegido deja al buscador en la posición de un guardia, su recompensa es de -100.
Si no es ninguno de los casos anteriores se utiliza la fórmula para el cálculo de las recompensas:
Q‘(s,a) <- r + gamma*max(Q (delta(s,a), a’))
Posibles acciones:
Las acciones están decididas de acuerdo a la posición actual del buscador. Para esto se creó una función que toma como argumento la posición (x, y) actual y determina de acuerdo a los choques que pueda tener las posibles direcciones que puede tomar el buscador. Estas acciones son almacenadas como números del 1 al 4, donde cada número representa una de las 4 direcciones que puede tomar para moverse, restringido por las paredes.
Estados:
Los estados están definidos por la posición actual del personaje, (x, y). Por lo que cada coordenada posible es un estado diferente. Cada par de coordenadas (x, y) están asignadas a un identificador, para facilitar la búsqueda de este estado.
Exploración:
A la constante gamma se le dio un valor de 0.6 para los cálculos, por lo que se lleva una exploración, sin embargo el espacio de estados es tan grande que muchas veces simplemente se la pasa explorando si no ha llegado al objetivo varias veces, o si el objetivo está muy lejos.
Ejemplos de estados:
Estado: 0 (21,21) (El estado inicial): En este caso hay paredes tanto arriba como abajo por lo que su acción es moverse a la izquierda o derecha.
Acción: 3, esto indica que se va a mover a la derecha.
Estado 10: (35, 15) Suponiendo que en este caso no hay paredes alrededor, puede decidir cualquier dirección.
Acciones posibles: [1, 2, 3, 4]
Acción tomada = 4, moverse a la izquierda.
Evaluación:
Para que el buscador se acerque al objetivo la mayoría de las veces, al asignar una recompensa de 100 al movimiento que lo llevo a tal estado, se utiliza una función para elegir un nuevo movimiento de acuerdo a las recompensas conocidas.
Si todas las recompensas son 0 para ese estado, entonces se toma una dirección aleatoria.
Si existe alguna que no es 0, entonces se toma la primera mayor recompensa (en caso de que haya múltiples con el mismo valor), es decir:
Acciones posibles: [1, 2. 3]
Recompensas:
1 -> 20
2-> 0
3-> 20
Movimiento/Acción tomada = 1.
Acciones posibles: [1, 2. 3]
Recompensas:
1 -> 0
2-> 0
3-> 0
Movimiento/Acción tomada = Movimiento aleatorio entre 1 y 3.
Acciones posibles: [1, 2. 3]
Recompensas:
1 -> -100
2-> 0
3-> 0
Movimiento/Acción tomada = 2.
Corridas:


Conclusiones:
Existen algunos pequeños errores, que más que nada se deben al medio ambiente y la velocidad con la que se actualiza. A veces interfiriendo por completo en el programa ya que le da una evaluación al encontrar el objetivo y el buscador deja de moverse, o arrojando números completamente exagerados, por cuestiones de la velocidad a la que se actualizan los datos.
En cuanto a la programación del algoritmo se puede observar en la segunda imagen, que al actualizar las recompensas se puede ver que si va aprendiendo que acción es la que debe tomar en ese caso. Sin embargo fue un problema el tener que tratar con un espacio de estados tan grande y a la vez con las restricciones de las paredes. Aunque si es un poco tedioso toda la exploración que hace a veces, sin embargo fue un algoritmo interesante de implementar en este ambiente.
Nuestro medio ambiente será como un tipo calabozo con forma de laberinto (el cuál será dinámico), constará de una entrada y dos tipos de agentes principales: buscador (agente verde) y guardián (agente rojo). También dentro del calabozo se encuentra un objeto que el buscador debe obtener (cuadro azul obscuro).
El objetivo del buscador será evitar a los guardias el mayor tiempo posible y a la vez, donde los callejones sin salida influirán a veces si es atrapado o no. El buscador debe encontrar el objetivo para de esta manera “ganar”.
En cuanto el agente buscador es atrapado por alguno de los guardianes, este regresa al inicio. También al encontrar el objetivo el buscador regresara a la entrada.
Actividad que aprende:
En este caso el agente aprenderá a moverse dentro del medio ambiente intentando acercarse lo más posible al objetivo.
Experiencia de Aprendizaje:
En este caso se utilizó el algoritmo de Q-Learning para que el agente buscador aprenda a encontrar su camino al objetivo (cuadro azul obscuro). El calabozo está situado en un cuadro de 40x40 donde el agente y los guardianes solo se mueven en los números impares, esto es coordenadas impares. Dado al tamaño el aprendizaje puede ser muy lento de acuerdo a los episodios seleccionados. Para esto se utiliza una variable entera, si esta es 1 quiere decir que el buscador obtuvo el objetivo, si es 2, significa que el buscador fue atrapado por uno de los guardias. Esto marca los episodios del aprendizaje.
Recompensas:
Las recompensas elegidas fueron las siguientes:
Si el movimiento elegido deja al buscador en la posición del objetivo, su recompensa es 100.
Si el movimiento elegido deja al buscador en la posición de un guardia, su recompensa es de -100.
Si no es ninguno de los casos anteriores se utiliza la fórmula para el cálculo de las recompensas:
Q‘(s,a) <- r + gamma*max(Q (delta(s,a), a’))
Posibles acciones:
Las acciones están decididas de acuerdo a la posición actual del buscador. Para esto se creó una función que toma como argumento la posición (x, y) actual y determina de acuerdo a los choques que pueda tener las posibles direcciones que puede tomar el buscador. Estas acciones son almacenadas como números del 1 al 4, donde cada número representa una de las 4 direcciones que puede tomar para moverse, restringido por las paredes.
Estados:
Los estados están definidos por la posición actual del personaje, (x, y). Por lo que cada coordenada posible es un estado diferente. Cada par de coordenadas (x, y) están asignadas a un identificador, para facilitar la búsqueda de este estado.
Exploración:
A la constante gamma se le dio un valor de 0.6 para los cálculos, por lo que se lleva una exploración, sin embargo el espacio de estados es tan grande que muchas veces simplemente se la pasa explorando si no ha llegado al objetivo varias veces, o si el objetivo está muy lejos.
Ejemplos de estados:
Estado: 0 (21,21) (El estado inicial): En este caso hay paredes tanto arriba como abajo por lo que su acción es moverse a la izquierda o derecha.
Acción: 3, esto indica que se va a mover a la derecha.
Estado 10: (35, 15) Suponiendo que en este caso no hay paredes alrededor, puede decidir cualquier dirección.
Acciones posibles: [1, 2, 3, 4]
Acción tomada = 4, moverse a la izquierda.
Evaluación:
Para que el buscador se acerque al objetivo la mayoría de las veces, al asignar una recompensa de 100 al movimiento que lo llevo a tal estado, se utiliza una función para elegir un nuevo movimiento de acuerdo a las recompensas conocidas.
Si todas las recompensas son 0 para ese estado, entonces se toma una dirección aleatoria.
Si existe alguna que no es 0, entonces se toma la primera mayor recompensa (en caso de que haya múltiples con el mismo valor), es decir:
Acciones posibles: [1, 2. 3]
Recompensas:
1 -> 20
2-> 0
3-> 20
Movimiento/Acción tomada = 1.
Acciones posibles: [1, 2. 3]
Recompensas:
1 -> 0
2-> 0
3-> 0
Movimiento/Acción tomada = Movimiento aleatorio entre 1 y 3.
Acciones posibles: [1, 2. 3]
Recompensas:
1 -> -100
2-> 0
3-> 0
Movimiento/Acción tomada = 2.
Corridas:
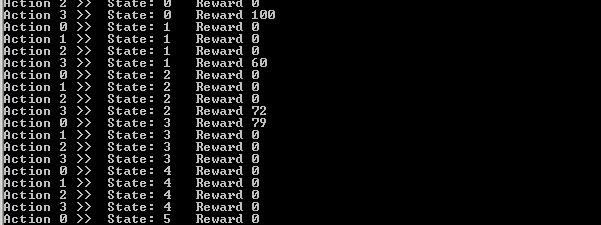

Conclusiones:
Existen algunos pequeños errores, que más que nada se deben al medio ambiente y la velocidad con la que se actualiza. A veces interfiriendo por completo en el programa ya que le da una evaluación al encontrar el objetivo y el buscador deja de moverse, o arrojando números completamente exagerados, por cuestiones de la velocidad a la que se actualizan los datos.
En cuanto a la programación del algoritmo se puede observar en la segunda imagen, que al actualizar las recompensas se puede ver que si va aprendiendo que acción es la que debe tomar en ese caso. Sin embargo fue un problema el tener que tratar con un espacio de estados tan grande y a la vez con las restricciones de las paredes. Aunque si es un poco tedioso toda la exploración que hace a veces, sin embargo fue un algoritmo interesante de implementar en este ambiente.
Friday, April 30, 2010
Medio Ambiente:
Nuestro medio ambiente será como un tipo calabozo con forma de laberinto (el cuál será dinámico), constará de una entrada y dos tipos de agentes principales: buscador y guardián
El objetivo del buscador será evitar a los guardias el mayor tiempo posible y a la vez, donde los callejones sin salida influirán a veces si es atrapado o no.
En cuanto el agente buscador es atrapado por alguno de los guardianes, este regresa al inicio.
Actividad que aprende:
En este caso el agente aprenderá a moverse dentro del medio ambiente intentando no ser atrapado por los guardianes. Para esto se utiliza una red neuronal que se entrena.
Patrones de Entrada:
Los patrones de entrada en este caso, se generan mediante iteraciones.
Los patrones cuentan con los siguientes datos:
a) [0, 1] Un valor booleano de si hay o no centinelas en su rango de visión.
b) [1 ,2, 3, 4] El valor de la dirección tomada para el movimiento.
c) [0, 1] Un valor booleano que determina si encontró un callejón sin salida o no en su camino.
d) [0, 1] Una evaluación de si la acción fue buena o mala.
Se escogieron estos valores ya que son los más importantes en este ambiente para poder moverse en el medio y cumplir la meta que se quiere aprender.
Patrones de Salida:
La salida que se genera es un arreglo de 4 atributos cuyo valor es 0 o 1, de tal forma que el siguiente movimiento del buscador será decidido por el índice o “bandera” que este prendida en el patrón de salida.
Ejemplo de patrón de salida:
[0, 0, 1, 0] -> El cual indicaría que el movimiento deberá tomar un valor de 3 (“Muévete a la derecha”)
Red Neuronal:
En este caso, dado que lo que se quiere evaluar es algo complejo, se decidió utilizar una red neuronal multicapas utilizando un algoritmo de Backpropagation.
La red cuenta con 3 capas
• Entrada: Esta capa cuenta con 4 neuronas, de las cuales cada una toma uno de los atributos de los patrones de entrada.
• Secreta: Esta capa consta de 2 neuronas, se decidió de esta forma para facilitar un poco la implementación y reducir un poco los cálculos.
• Salida: Esta capa cuenta con 4 neuronas, para las cuales cada una sirve como bandera para elegir el siguiente movimiento, dependiendo de que neurona se active es el movimiento elegido.
En la red se utiliza un factor de aprendizaje de 0.3 ya que es un valor pequeño y un tanto “estándar”: ya que queremos que el aprendizaje sea preciso en cuanto a las salidas.
En este caso no se utilizo momento.
El número de iteraciones elegido para entrenar a la red fue de 1500 ya que al ser movimientos aleatorios al principio, es de interés que tenga una exploración del ambiente bastante grande para poder hacer la red neuronal más precisa
Ejemplos de corridas:

En la imagen se puede observar del lado izquierdo las entradas que va generando, y del lado derecho la salida que se debería dar, pero dado a que solo se está entrenando apenas la red, los valores de salida no son realmente acertados. Si se ven por ejemplo la primera línea:
Patrón de entrada: [0, 0, 4, 1]
Salida: [0, 0, 1, 0] Mientras que la salida esperada sería [0, 0, 0, 1]

Después de que ha terminado las iteraciones de entrenamiento podemos ver, que de acuerdo al patrón de entrada, ahora si nos envía la salida esperada:
Ejemplo de la primera línea:
Entrada: [0, 0, 4, 1]
Valor esperado: [0, 0, 0, 1]
Como se observa en la imagen, el valor obtenido es igual al esperado, por lo que la red aprendió efectivamente.
Conclusiones:
Las redes neuronales son bastante útiles para problemas como el presentado ya que sus cálculos y división en las salidas nos permite una evaluación y un aprendizaje más preciso asignando una dirección a cada salida. También es importante notar que la velocidad de los cálculos es importante, y en este caso es lo suficientemente rápida para un programa que se actualiza en tiempo real, lo que hace una red neuronal muy viable para este tipo de problemas.
La parte más difícil para este proyecto se podría considerar la codificación de entradas y salidas del medio ambiente, ya que todos los cálculos internos son automáticos del algoritmo.
Nuestro medio ambiente será como un tipo calabozo con forma de laberinto (el cuál será dinámico), constará de una entrada y dos tipos de agentes principales: buscador y guardián
El objetivo del buscador será evitar a los guardias el mayor tiempo posible y a la vez, donde los callejones sin salida influirán a veces si es atrapado o no.
En cuanto el agente buscador es atrapado por alguno de los guardianes, este regresa al inicio.
Actividad que aprende:
En este caso el agente aprenderá a moverse dentro del medio ambiente intentando no ser atrapado por los guardianes. Para esto se utiliza una red neuronal que se entrena.
Patrones de Entrada:
Los patrones de entrada en este caso, se generan mediante iteraciones.
Los patrones cuentan con los siguientes datos:
a) [0, 1] Un valor booleano de si hay o no centinelas en su rango de visión.
b) [1 ,2, 3, 4] El valor de la dirección tomada para el movimiento.
c) [0, 1] Un valor booleano que determina si encontró un callejón sin salida o no en su camino.
d) [0, 1] Una evaluación de si la acción fue buena o mala.
Se escogieron estos valores ya que son los más importantes en este ambiente para poder moverse en el medio y cumplir la meta que se quiere aprender.
Patrones de Salida:
La salida que se genera es un arreglo de 4 atributos cuyo valor es 0 o 1, de tal forma que el siguiente movimiento del buscador será decidido por el índice o “bandera” que este prendida en el patrón de salida.
Ejemplo de patrón de salida:
[0, 0, 1, 0] -> El cual indicaría que el movimiento deberá tomar un valor de 3 (“Muévete a la derecha”)
Red Neuronal:
En este caso, dado que lo que se quiere evaluar es algo complejo, se decidió utilizar una red neuronal multicapas utilizando un algoritmo de Backpropagation.
La red cuenta con 3 capas
• Entrada: Esta capa cuenta con 4 neuronas, de las cuales cada una toma uno de los atributos de los patrones de entrada.
• Secreta: Esta capa consta de 2 neuronas, se decidió de esta forma para facilitar un poco la implementación y reducir un poco los cálculos.
• Salida: Esta capa cuenta con 4 neuronas, para las cuales cada una sirve como bandera para elegir el siguiente movimiento, dependiendo de que neurona se active es el movimiento elegido.
En la red se utiliza un factor de aprendizaje de 0.3 ya que es un valor pequeño y un tanto “estándar”: ya que queremos que el aprendizaje sea preciso en cuanto a las salidas.
En este caso no se utilizo momento.
El número de iteraciones elegido para entrenar a la red fue de 1500 ya que al ser movimientos aleatorios al principio, es de interés que tenga una exploración del ambiente bastante grande para poder hacer la red neuronal más precisa
Ejemplos de corridas:

En la imagen se puede observar del lado izquierdo las entradas que va generando, y del lado derecho la salida que se debería dar, pero dado a que solo se está entrenando apenas la red, los valores de salida no son realmente acertados. Si se ven por ejemplo la primera línea:
Patrón de entrada: [0, 0, 4, 1]
Salida: [0, 0, 1, 0] Mientras que la salida esperada sería [0, 0, 0, 1]

Después de que ha terminado las iteraciones de entrenamiento podemos ver, que de acuerdo al patrón de entrada, ahora si nos envía la salida esperada:
Ejemplo de la primera línea:
Entrada: [0, 0, 4, 1]
Valor esperado: [0, 0, 0, 1]
Como se observa en la imagen, el valor obtenido es igual al esperado, por lo que la red aprendió efectivamente.
Conclusiones:
Las redes neuronales son bastante útiles para problemas como el presentado ya que sus cálculos y división en las salidas nos permite una evaluación y un aprendizaje más preciso asignando una dirección a cada salida. También es importante notar que la velocidad de los cálculos es importante, y en este caso es lo suficientemente rápida para un programa que se actualiza en tiempo real, lo que hace una red neuronal muy viable para este tipo de problemas.
La parte más difícil para este proyecto se podría considerar la codificación de entradas y salidas del medio ambiente, ya que todos los cálculos internos son automáticos del algoritmo.
Biokterii Neural
Breve descripción del medio ambiente.
El medio consiste en el interior de un cuerpo de un ser vivo en el que un virus debe aprender a reconocer células a partir de la observación de sus características. Existen tres zonas diferentes de clasificación de células, unas de ellas son comestibles o de tipo Food, otras son aquellas que pueden atacar al virus o Enemy, por último nos encontramos con las células objetivo o de tipo Target. El virus deberá aprender, después de una muestra de 15 células, a determinar el tipo de las células que irán apareciendo, actuar en consecuencia y así poder sobrevivir dentro del cuerpo del ser vivo.
Descripción detallada de la actividad o acción que va a aprender tu agente.
El virus debe aprender a reconocer las células que irá encontrando dentro del cuerpo, para esto se basa en sus características físicas, es decir, su color, su forma, la dirección en la que rota, la figura que tiene la célula en su interior y el color de esta figura interna. Como ya se mencionó en un principio, se cuenta con 15 células que formarán parte del entrenamiento, que el usuario puede acomodar en cualquiera de las tres categorías: Target, Enemy o Food. Es muy importante mencionar que dependiendo como el usuario haga esta clasificación, será la forma en que la neurona aprenderá a clasificar las diferentes células que irán apareciendo en el ambiente, ya que el usuario crea interactivamente el training set.
Solución planteada al problema utilizando Redes Neuronales. Describe con detalle cada elemento del planteamiento:
Cada célula tiene 5 propiedades: Forma exterior color exterior, forma y color interior y rotación. De cada una se tiene un arreglo de bits que indican el tipo de característica que representa a cada célula, que se codifica concatenando los 5 arreglos de bits en un arreglo más grande que los contiene a todos. Cada bit alimenta a un nodo diferente en la capa de entrada. Dependiendo de la clasificación del usuario, es la forma en la que se entrena la red.
Se utilizó la biblioteca PyBrain para la construcción de las redes neuronales.
i. Patrones de aprendizaje para alimentar a la red.
OuterShape: ["Simple","CircleStroke","CircleFill","Square","DoubleSquare"]
InnerShape: ["None","CircleStroke","CircleFill","SquareStroke","SquareFill"]
OuterColor: ["Red","Green","Blue"]
InnerColor: ["Red", "Green", "Blue", "Black"]
Rotation: ["Left", "Right"]
OuterShape= [0,0,0,0,1]
InnerShape= [0,0,0,0,1]
OuterColor= [0,1,0]
InnerColor= [1,0,0,0]
Rotation= [1,0]
Clasificación (elegida por el usuario): ["Target","Enemy","Food"]
Clasificación = [0,1,0]
---------------------------------------------------------------------------------
Patrón de aprendizaje: ([0,0,0,0,1,0,0,0,0,1,0,1,0,1,0,0,0,1,0] , [0,1,0])
---------------------------------------------------------------------------------
Se alimentarán tantos patrones como células iniciales existan en el medio ambiente, seleccionando el 25% de ellas para pruebas durante el entrenamiento.
ii. Codificación de la salida de la red.
La red devuelve un arreglo de 3 datos que representan la probabilidad de ser clasificado como cada uno de los posibles tipos: objetivo enemigo y comida.
Se elige el tipo que tenga el número más alto de los tres para clasificar.
Ejemplo, la salida:
[0.0032896,0.2387263,0.87382436]
Clasifica a la célula como "Comida" pues el elemento más alto es el tercero, que representa la posibilidad de ser "Comida".
iii. Tipo de red neuronal a ser utilizada.
La red neuronal está formada por 3 capas, la primera es una capa lineal, la segunda sigmoidal y la tercera lineal, de tal forma que existe una conexión completa de los nodos entre cada capa llevando de los 19 parámetros de entrada originales a las 3 salidas deseadas.
iv. Numero de capas (entrada, intermedias, salida) y número de neuronas en cada capa.
v. Parámetros de la red (tasa de aprendizaje, momento, iteraciones).
Se utilizó una tasa de aprendizaje de 0.3 y un momento de 0.1.
Se realizan iteraciones hasta que converge la red o hasta que se cumplan 1000 iteraciones.
Video
Conclusiones
Una de las características observadas a lo largo de la programación del problema fue la importancia que tiene el training set para la solución del mismo. En particular, las redes neuronales requieren de mucho entrenamiento, lo cual implica tener un training set muy grande y diverso. Si no existiera suficiente entrenamiento la red sería muy suceptible al ruido, por lo que funcionan mejor learning rates más bajos, de tal forma que aprenda detalles más finos del training set. La red neuronal, sin embargo, requiere mucho más tiempo de entrenamiento que otros algoritmos como el ID3, por lo que su implementación no sería adecuada para generarse en un ambiente que requiera de cambios en tiempo real.
El medio consiste en el interior de un cuerpo de un ser vivo en el que un virus debe aprender a reconocer células a partir de la observación de sus características. Existen tres zonas diferentes de clasificación de células, unas de ellas son comestibles o de tipo Food, otras son aquellas que pueden atacar al virus o Enemy, por último nos encontramos con las células objetivo o de tipo Target. El virus deberá aprender, después de una muestra de 15 células, a determinar el tipo de las células que irán apareciendo, actuar en consecuencia y así poder sobrevivir dentro del cuerpo del ser vivo.
Descripción detallada de la actividad o acción que va a aprender tu agente.
El virus debe aprender a reconocer las células que irá encontrando dentro del cuerpo, para esto se basa en sus características físicas, es decir, su color, su forma, la dirección en la que rota, la figura que tiene la célula en su interior y el color de esta figura interna. Como ya se mencionó en un principio, se cuenta con 15 células que formarán parte del entrenamiento, que el usuario puede acomodar en cualquiera de las tres categorías: Target, Enemy o Food. Es muy importante mencionar que dependiendo como el usuario haga esta clasificación, será la forma en que la neurona aprenderá a clasificar las diferentes células que irán apareciendo en el ambiente, ya que el usuario crea interactivamente el training set.
Solución planteada al problema utilizando Redes Neuronales. Describe con detalle cada elemento del planteamiento:
Cada célula tiene 5 propiedades: Forma exterior color exterior, forma y color interior y rotación. De cada una se tiene un arreglo de bits que indican el tipo de característica que representa a cada célula, que se codifica concatenando los 5 arreglos de bits en un arreglo más grande que los contiene a todos. Cada bit alimenta a un nodo diferente en la capa de entrada. Dependiendo de la clasificación del usuario, es la forma en la que se entrena la red.
Se utilizó la biblioteca PyBrain para la construcción de las redes neuronales.
i. Patrones de aprendizaje para alimentar a la red.
OuterShape: ["Simple","CircleStroke","CircleFill","Square","DoubleSquare"]
InnerShape: ["None","CircleStroke","CircleFill","SquareStroke","SquareFill"]
OuterColor: ["Red","Green","Blue"]
InnerColor: ["Red", "Green", "Blue", "Black"]
Rotation: ["Left", "Right"]
OuterShape= [0,0,0,0,1]
InnerShape= [0,0,0,0,1]
OuterColor= [0,1,0]
InnerColor= [1,0,0,0]
Rotation= [1,0]
Clasificación (elegida por el usuario): ["Target","Enemy","Food"]
Clasificación = [0,1,0]
---------------------------------------------------------------------------------
Patrón de aprendizaje: ([0,0,0,0,1,0,0,0,0,1,0,1,0,1,0,0,0,1,0] , [0,1,0])
---------------------------------------------------------------------------------
Se alimentarán tantos patrones como células iniciales existan en el medio ambiente, seleccionando el 25% de ellas para pruebas durante el entrenamiento.
ii. Codificación de la salida de la red.
La red devuelve un arreglo de 3 datos que representan la probabilidad de ser clasificado como cada uno de los posibles tipos: objetivo enemigo y comida.
Se elige el tipo que tenga el número más alto de los tres para clasificar.
Ejemplo, la salida:
[0.0032896,0.2387263,0.87382436]
Clasifica a la célula como "Comida" pues el elemento más alto es el tercero, que representa la posibilidad de ser "Comida".
iii. Tipo de red neuronal a ser utilizada.
La red neuronal está formada por 3 capas, la primera es una capa lineal, la segunda sigmoidal y la tercera lineal, de tal forma que existe una conexión completa de los nodos entre cada capa llevando de los 19 parámetros de entrada originales a las 3 salidas deseadas.
iv. Numero de capas (entrada, intermedias, salida) y número de neuronas en cada capa.
v. Parámetros de la red (tasa de aprendizaje, momento, iteraciones).
Se utilizó una tasa de aprendizaje de 0.3 y un momento de 0.1.
Se realizan iteraciones hasta que converge la red o hasta que se cumplan 1000 iteraciones.
Video
Conclusiones
Una de las características observadas a lo largo de la programación del problema fue la importancia que tiene el training set para la solución del mismo. En particular, las redes neuronales requieren de mucho entrenamiento, lo cual implica tener un training set muy grande y diverso. Si no existiera suficiente entrenamiento la red sería muy suceptible al ruido, por lo que funcionan mejor learning rates más bajos, de tal forma que aprenda detalles más finos del training set. La red neuronal, sin embargo, requiere mucho más tiempo de entrenamiento que otros algoritmos como el ID3, por lo que su implementación no sería adecuada para generarse en un ambiente que requiera de cambios en tiempo real.
Actividad: Redes Neuronales
Descripción del medio ambiente
En una playa, están naciendo varias tortugas, y para sobrevivir, deben de llegar al mar lo más rápido posible, sin embargo, puede que haya depredadores cerca queriendo alimentarse de ellas, lo que las hace más vulnerables. Las tortugas nacen a cierta distancia del mar, además de nacer con cierta velocidad propia y cierta resistencia a los ataques de los depredadores.
Descripción de la actividad que aprenderá el agente
Dadas las características de cada tortuga (su distancia al mar, si hay o no depredador cerca, su velocidad y su resistencia), el agente debe de decidir si una tortuga se salva sin ayuda de nadie, si es necesaria la intervención humana para salvarla o si es imposible salvarla.
Descripción detallada de los patrones
Un patrón está formado de la siguiente manera:
{ Distancia, Depredador, Velocidad, Resistencia} ¿Se salva?
Donde:
Distancia mide si se encuentra entre 0-5 metros, 5-10 metros o más de 10 metros. Se eligió así para evitar que los patrones fueran continuos y se eligieron esos rangos porque creemos que son distancias que pueden hacer diferencia entre si la tortuga vive o no.
Depredador mide solamente si hay o no un depredador cerca de la tortuga, donde cerca se define dentro del área de sobrevivencia de la tortuga, que son de alrededor de 5 metros a la redonda. Nuevamente, creemos que este radio es el que puede hacer la diferencia entre si la tortuga sobrevive o no.
Velocidad, mide qué tan rápido se mueve la tortuga, y cae dentro de: Lento, Normal o Rápido.
Resistencia, mide que tanto la tortuga puede resistir a los ataques de los depredadores, y esta puede ser Alta, Media y Baja. Estos últimos dos atributos se discretizaron para poder trabajar con ellos y se escogieron ya que una tortuga rápida puede llegar al mar pese a estar lejos o viceversa, y ocurre similar con la resistencia.
Cada uno de los valores de entrada, están codificados en 0.1, 0.5 ó 0.9 según sea bajo, mediano o alto.
¿Se salva? Es un valor ternario (también entre 0.1,0.5 o 0.9) que identifica si la tortuga se salva sola, si hay que salvarla o si no hay forma alguna de salvarla.
Red Neuronal
Para poder lograr que la red aprendiese cuando y cuando no salvar a la tortuga, programamos una red neuronal estocástica con valores decimales entre 0 y 1.
Existen cinco valores de entrada, la primera corresponde al valor 1.0 (para pasar el threshold) y las siguientes cuatro corresponden a los cuatro valores de entrada de la red, organizados, como ya se explicó entre 0.1, 0.5 y 0.9.
Se cuenta con una capa oculta de tres neuronas ya que es el valor que se recomienda para redes pequeñas.
De salida sólo se tiene una neurona, que identifica de igual forma 0.1, 0.5 o 0.9 según sea la salida. No fue necesario poner tres neuronas cada una para identificar un tipo de clase ya que sí logró clasificar los ejemplos con una sola neurona.
Para entrenar la red, se utilizó una tasa de aprendizaje de 0.35, ya que un valor más alto causaba que los ejemplos de validación se alejaran más del resultado, lo cual atribuimos al overfitting, y un valor más pequeño hacía demasiado tardada el aprendizaje.
No se utilizó ningún momento porque no fue necesario implementarse para lograr que la red clasificara correctamente los ejemplos de salida.Se utilizaron 15 ejemplos de entrenamiento y cinco ejemplos de validación, aunque para terminar el programa, se decidió que cuando el error en los ejemplos de entrenamiento fuera menor a 0.1, este se detuviera.
Los resultados con los ejemplos de validación son los siguientes:
Antes del entrenamiento
0.9 0.1 0.1 0.9 à Salida esperada: 0.1 à Salida del programa: 0.4973
0.1 0.1 0.9 0.5 à Salida esperada: 0.1 à Salida del programa: 0.4933
0.5 0.5 0.9 0.9 àSalida esperada: 0.5 à Salida del programa: 0.4976
0.9 0.5 0.1 0.1 à Salida esperada: 0.9 à Salida del programa: 0.4838
0.5 0.5 0.5 0.1 à Salida esperada: 0.5 à Salida del programa: 0.4943
Después del entrenamiento
0.9 0.1 0.1 0.9 à Salida esperada: 0.1 à Salida del programa: 0.1932
0.1 0.1 0.9 0.5 à Salida esperada: 0.1 à Salida del programa: 0.0587
0.5 0.5 0.9 0.9 àSalida esperada: 0.5 à Salida del programa: 0.3205
0.9 0.5 0.1 0.1 à Salida esperada: 0.9 à Salida del programa: 0.6738
0.5 0.5 0.5 0.1 à Salida esperada: 0.5 à Salida del programa: 0.5100
Tomando en cuenta que un valor pertenece a la clase siempre que el valor este entre 0.15 arriba o abajo del valor esperado, este clasifica correctamente, todos los patrones fueron clasificados.
Conclusiones
En conclusión, creemos que las redes neuronales son bastante difíciles de implementar, debido a que hay que estar probando con diferentes valores de capas intermedias, además de poner el número de neuronas correctas en cada capa, para lo cual, la única forma de saberlo es probarlo sobre la propia red. También hay que tener cuidado con la codificación de los datos de entrada y de los datos de salida, porque es posible que no llegue a generalizar si los valores de salida son muy cercanos.
Fuera de eso, fue muy entretenido generar la red e implementarla, aunque llegó a ser complejo por toda la cantidad de datos e información que hay que tomar en cuenta para lograr una correcta generalización.
Preferimos desarrollar una red neuronal a un algoritmo como ID3 ya que en ocasiones ID3 puede no tener un ejemplo para cierto patrón, en cambio una red tratará de dar el que más se acerque de acuerdo a los ejemplos de entrenamiento.
En una playa, están naciendo varias tortugas, y para sobrevivir, deben de llegar al mar lo más rápido posible, sin embargo, puede que haya depredadores cerca queriendo alimentarse de ellas, lo que las hace más vulnerables. Las tortugas nacen a cierta distancia del mar, además de nacer con cierta velocidad propia y cierta resistencia a los ataques de los depredadores.
Descripción de la actividad que aprenderá el agente
Dadas las características de cada tortuga (su distancia al mar, si hay o no depredador cerca, su velocidad y su resistencia), el agente debe de decidir si una tortuga se salva sin ayuda de nadie, si es necesaria la intervención humana para salvarla o si es imposible salvarla.
Descripción detallada de los patrones
Un patrón está formado de la siguiente manera:
{ Distancia, Depredador, Velocidad, Resistencia} ¿Se salva?
Donde:
Distancia mide si se encuentra entre 0-5 metros, 5-10 metros o más de 10 metros. Se eligió así para evitar que los patrones fueran continuos y se eligieron esos rangos porque creemos que son distancias que pueden hacer diferencia entre si la tortuga vive o no.
Depredador mide solamente si hay o no un depredador cerca de la tortuga, donde cerca se define dentro del área de sobrevivencia de la tortuga, que son de alrededor de 5 metros a la redonda. Nuevamente, creemos que este radio es el que puede hacer la diferencia entre si la tortuga sobrevive o no.
Velocidad, mide qué tan rápido se mueve la tortuga, y cae dentro de: Lento, Normal o Rápido.
Resistencia, mide que tanto la tortuga puede resistir a los ataques de los depredadores, y esta puede ser Alta, Media y Baja. Estos últimos dos atributos se discretizaron para poder trabajar con ellos y se escogieron ya que una tortuga rápida puede llegar al mar pese a estar lejos o viceversa, y ocurre similar con la resistencia.
Cada uno de los valores de entrada, están codificados en 0.1, 0.5 ó 0.9 según sea bajo, mediano o alto.
¿Se salva? Es un valor ternario (también entre 0.1,0.5 o 0.9) que identifica si la tortuga se salva sola, si hay que salvarla o si no hay forma alguna de salvarla.
Red Neuronal
Para poder lograr que la red aprendiese cuando y cuando no salvar a la tortuga, programamos una red neuronal estocástica con valores decimales entre 0 y 1.
Existen cinco valores de entrada, la primera corresponde al valor 1.0 (para pasar el threshold) y las siguientes cuatro corresponden a los cuatro valores de entrada de la red, organizados, como ya se explicó entre 0.1, 0.5 y 0.9.
Se cuenta con una capa oculta de tres neuronas ya que es el valor que se recomienda para redes pequeñas.
De salida sólo se tiene una neurona, que identifica de igual forma 0.1, 0.5 o 0.9 según sea la salida. No fue necesario poner tres neuronas cada una para identificar un tipo de clase ya que sí logró clasificar los ejemplos con una sola neurona.
Para entrenar la red, se utilizó una tasa de aprendizaje de 0.35, ya que un valor más alto causaba que los ejemplos de validación se alejaran más del resultado, lo cual atribuimos al overfitting, y un valor más pequeño hacía demasiado tardada el aprendizaje.
No se utilizó ningún momento porque no fue necesario implementarse para lograr que la red clasificara correctamente los ejemplos de salida.Se utilizaron 15 ejemplos de entrenamiento y cinco ejemplos de validación, aunque para terminar el programa, se decidió que cuando el error en los ejemplos de entrenamiento fuera menor a 0.1, este se detuviera.
Los resultados con los ejemplos de validación son los siguientes:
Antes del entrenamiento
0.9 0.1 0.1 0.9 à Salida esperada: 0.1 à Salida del programa: 0.4973
0.1 0.1 0.9 0.5 à Salida esperada: 0.1 à Salida del programa: 0.4933
0.5 0.5 0.9 0.9 àSalida esperada: 0.5 à Salida del programa: 0.4976
0.9 0.5 0.1 0.1 à Salida esperada: 0.9 à Salida del programa: 0.4838
0.5 0.5 0.5 0.1 à Salida esperada: 0.5 à Salida del programa: 0.4943
Después del entrenamiento
0.9 0.1 0.1 0.9 à Salida esperada: 0.1 à Salida del programa: 0.1932
0.1 0.1 0.9 0.5 à Salida esperada: 0.1 à Salida del programa: 0.0587
0.5 0.5 0.9 0.9 àSalida esperada: 0.5 à Salida del programa: 0.3205
0.9 0.5 0.1 0.1 à Salida esperada: 0.9 à Salida del programa: 0.6738
0.5 0.5 0.5 0.1 à Salida esperada: 0.5 à Salida del programa: 0.5100
Tomando en cuenta que un valor pertenece a la clase siempre que el valor este entre 0.15 arriba o abajo del valor esperado, este clasifica correctamente, todos los patrones fueron clasificados.
Conclusiones
En conclusión, creemos que las redes neuronales son bastante difíciles de implementar, debido a que hay que estar probando con diferentes valores de capas intermedias, además de poner el número de neuronas correctas en cada capa, para lo cual, la única forma de saberlo es probarlo sobre la propia red. También hay que tener cuidado con la codificación de los datos de entrada y de los datos de salida, porque es posible que no llegue a generalizar si los valores de salida son muy cercanos.
Fuera de eso, fue muy entretenido generar la red e implementarla, aunque llegó a ser complejo por toda la cantidad de datos e información que hay que tomar en cuenta para lograr una correcta generalización.
Preferimos desarrollar una red neuronal a un algoritmo como ID3 ya que en ocasiones ID3 puede no tener un ejemplo para cierto patrón, en cambio una red tratará de dar el que más se acerque de acuerdo a los ejemplos de entrenamiento.
Thursday, April 8, 2010
Actividad de Programación 3: Algoritmo ID3
Medio Ambiente:
Nuestro medio ambiente será como un tipo calabozo con forma de laberinto (el cuál será dinámico), constará de una entrada y una salida Y tres tipos de agentes principales: buscador, guardián y espía. El agente buscador se encargará de buscar un objeto y huir hacia la salida, evitando lo más que pueda al agente guardián. El agente guardián se encargará de hacer rondas en el calabozo en diferentes zonas (mientras las va conociendo y aprendiendo) y en cuanto encuentre al agente buscador, seguirlo para capturarlo. El agente espía se encargará de ayudar al agente buscador para encontrar el objeto verdadero, indicándole dónde hay atajos e interfiriendo en las comunicaciones de los agentes guardianes (solo en el caso que exista más de un agente guardián). Puede que existan más buscadores y de ésta forma los agentes guardianes se confundirán.
En caso de que solo existiera una entrada, se tendría que conseguir el objeto único que podrá convertir la entrada en la salida, para esto, nuestro agente tendría que recordar el camino por el que vino, siempre tratando de evitar al agente guardia.
Existirán agentes guardias, los cuales estarán recorriendo todo el calabozo para conocer el terreno y estar haciendo guardia en algunas de las zonas del mismo. Dentro del calabozo existen diversos objetos, de los cuales hay uno que es el que le abrirá la puerta a la salida, pero hay objetos falsos, copias, que tratarán de confundir al agente buscador.
Actividad que aprende:
En este caso el agente aprenderá a moverse dentro del medio ambiente intentando no ser atrapado por los centinelas. Utilizando el algoritmo de ID3 este aprende en qué dirección moverse de acuerdo a la retroalimentación obtenida.
Patrones:
Los patrones de entrenamiento en este caso, se generan por 30 segundos a partir de que el programa corre. Los patrones cuentan con los siguientes datos:
a) [0, 1] Un valor booleano de si hay o no centinelas en su rango de visión.
b) [1 ,2, 3, 4] El valor de la dirección tomada para el movimiento.
c) [0, 1] Un valor booleano que determina si encontró un callejón sin salida o no en su camino.
d) [0, 1] Una evaluación de si la acción fue buena o mala.
Se escogieron estos valores ya que son los más importantes en este ambiente para poder moverse en el medio y cumplir la meta que se quiere aprender. Además de que son valores fáciles de evaluar para la utilización del algoritmo.
Los patrones se irán almacenando en un arreglo bidimensional.
Solución ID3:
i) Algoritmo utilizado:
a. ID3: Ya que fue interesante la implementación de este en el medio ambiente y porque es sencillo de comprender.
ii)
a. Aprendizaje: El número de patrones realmente no está definido ya que está delimitado por tiempo, en este caso se generan patrones, cada que el agente se mueve y que se repinta la pantalla durante 30 segundos. Terminando el lapso de 30 segundos el movimiento se determina de acuerdo al algoritmo.
b. Validación: En este caso no se utilizan patrones de validación ya que nosotros no tenemos control sobre el movimiento del agente, simplemente al ser movimientos aleatorios, el programa utiliza el árbol generado con los patrones de entrenamiento para ir evaluando paso por paso el movimiento del agente, en el caso de tener una retroalimentación buena sigue el camino, en caso de tener una retroalimentación mala, se mueve en dirección contraria.
c. Ejemplos:
iii) Este programa si funciona en tiempo real, ya que por eso se está corriendo por tiempo, durante un tiempo se entrena y todo lo que resta del tiempo está generando movimientos a partir de lo que aprendió con ID3 cada paso o movimiento que hace.
iv) No cuenta con overfitting ya que el movimiento del agente es aleatorio, entonces puede darse el caso de que muchos casos no estén considerados dentro del lapso de tiempo que se asignó para generar patrones de entrenamiento.
v) Mejorar el funcionamiento podría ser agregando más valores a los patrones de entrenamiento ya que en la forma que está ahorita sería una forma simple, pero en un ambiente más complicado podría llegar a no funcionar bien con tan pocos valores o patrones. También se podría aumentar el tiempo que genera patrones de entrenamiento.
Conclusiones:
Esta actividad nos ayudo a comprender mejor la forma en que se lleva a cabo la relación entre el árbol de decisiones generado por ID3 y el medio ambiente, llegando así a un aprendizaje. A la vez pudimos ver que no es un algoritmo muy complejo de programar, sino su dificultad está en adaptarse a un medio diferente por todas las variables que hay que tomar en cuenta, a la vez de que se deben decidir los patrones.
Probablemente la parte de la decisión de que valores utilizar para los patrones fue el más difícil ya que de esto dependía el funcionamiento completo del algoritmo.
Nuestro medio ambiente será como un tipo calabozo con forma de laberinto (el cuál será dinámico), constará de una entrada y una salida Y tres tipos de agentes principales: buscador, guardián y espía. El agente buscador se encargará de buscar un objeto y huir hacia la salida, evitando lo más que pueda al agente guardián. El agente guardián se encargará de hacer rondas en el calabozo en diferentes zonas (mientras las va conociendo y aprendiendo) y en cuanto encuentre al agente buscador, seguirlo para capturarlo. El agente espía se encargará de ayudar al agente buscador para encontrar el objeto verdadero, indicándole dónde hay atajos e interfiriendo en las comunicaciones de los agentes guardianes (solo en el caso que exista más de un agente guardián). Puede que existan más buscadores y de ésta forma los agentes guardianes se confundirán.
En caso de que solo existiera una entrada, se tendría que conseguir el objeto único que podrá convertir la entrada en la salida, para esto, nuestro agente tendría que recordar el camino por el que vino, siempre tratando de evitar al agente guardia.
Existirán agentes guardias, los cuales estarán recorriendo todo el calabozo para conocer el terreno y estar haciendo guardia en algunas de las zonas del mismo. Dentro del calabozo existen diversos objetos, de los cuales hay uno que es el que le abrirá la puerta a la salida, pero hay objetos falsos, copias, que tratarán de confundir al agente buscador.
Actividad que aprende:
En este caso el agente aprenderá a moverse dentro del medio ambiente intentando no ser atrapado por los centinelas. Utilizando el algoritmo de ID3 este aprende en qué dirección moverse de acuerdo a la retroalimentación obtenida.
Patrones:
Los patrones de entrenamiento en este caso, se generan por 30 segundos a partir de que el programa corre. Los patrones cuentan con los siguientes datos:
a) [0, 1] Un valor booleano de si hay o no centinelas en su rango de visión.
b) [1 ,2, 3, 4] El valor de la dirección tomada para el movimiento.
c) [0, 1] Un valor booleano que determina si encontró un callejón sin salida o no en su camino.
d) [0, 1] Una evaluación de si la acción fue buena o mala.
Se escogieron estos valores ya que son los más importantes en este ambiente para poder moverse en el medio y cumplir la meta que se quiere aprender. Además de que son valores fáciles de evaluar para la utilización del algoritmo.
Los patrones se irán almacenando en un arreglo bidimensional.
Solución ID3:
i) Algoritmo utilizado:
a. ID3: Ya que fue interesante la implementación de este en el medio ambiente y porque es sencillo de comprender.
ii)
a. Aprendizaje: El número de patrones realmente no está definido ya que está delimitado por tiempo, en este caso se generan patrones, cada que el agente se mueve y que se repinta la pantalla durante 30 segundos. Terminando el lapso de 30 segundos el movimiento se determina de acuerdo al algoritmo.
b. Validación: En este caso no se utilizan patrones de validación ya que nosotros no tenemos control sobre el movimiento del agente, simplemente al ser movimientos aleatorios, el programa utiliza el árbol generado con los patrones de entrenamiento para ir evaluando paso por paso el movimiento del agente, en el caso de tener una retroalimentación buena sigue el camino, en caso de tener una retroalimentación mala, se mueve en dirección contraria.
c. Ejemplos:
iii) Este programa si funciona en tiempo real, ya que por eso se está corriendo por tiempo, durante un tiempo se entrena y todo lo que resta del tiempo está generando movimientos a partir de lo que aprendió con ID3 cada paso o movimiento que hace.
iv) No cuenta con overfitting ya que el movimiento del agente es aleatorio, entonces puede darse el caso de que muchos casos no estén considerados dentro del lapso de tiempo que se asignó para generar patrones de entrenamiento.
v) Mejorar el funcionamiento podría ser agregando más valores a los patrones de entrenamiento ya que en la forma que está ahorita sería una forma simple, pero en un ambiente más complicado podría llegar a no funcionar bien con tan pocos valores o patrones. También se podría aumentar el tiempo que genera patrones de entrenamiento.
Conclusiones:
Esta actividad nos ayudo a comprender mejor la forma en que se lleva a cabo la relación entre el árbol de decisiones generado por ID3 y el medio ambiente, llegando así a un aprendizaje. A la vez pudimos ver que no es un algoritmo muy complejo de programar, sino su dificultad está en adaptarse a un medio diferente por todas las variables que hay que tomar en cuenta, a la vez de que se deben decidir los patrones.
Probablemente la parte de la decisión de que valores utilizar para los patrones fue el más difícil ya que de esto dependía el funcionamiento completo del algoritmo.
Subscribe to:
Posts (Atom)